많은 한국 기업이 AI 도입을 선언하고 있습니다. 그런데 왜 사업 구조는 바뀌지 않는가 — AI 전환 전략의 문제
지금 일어나고 있는 일
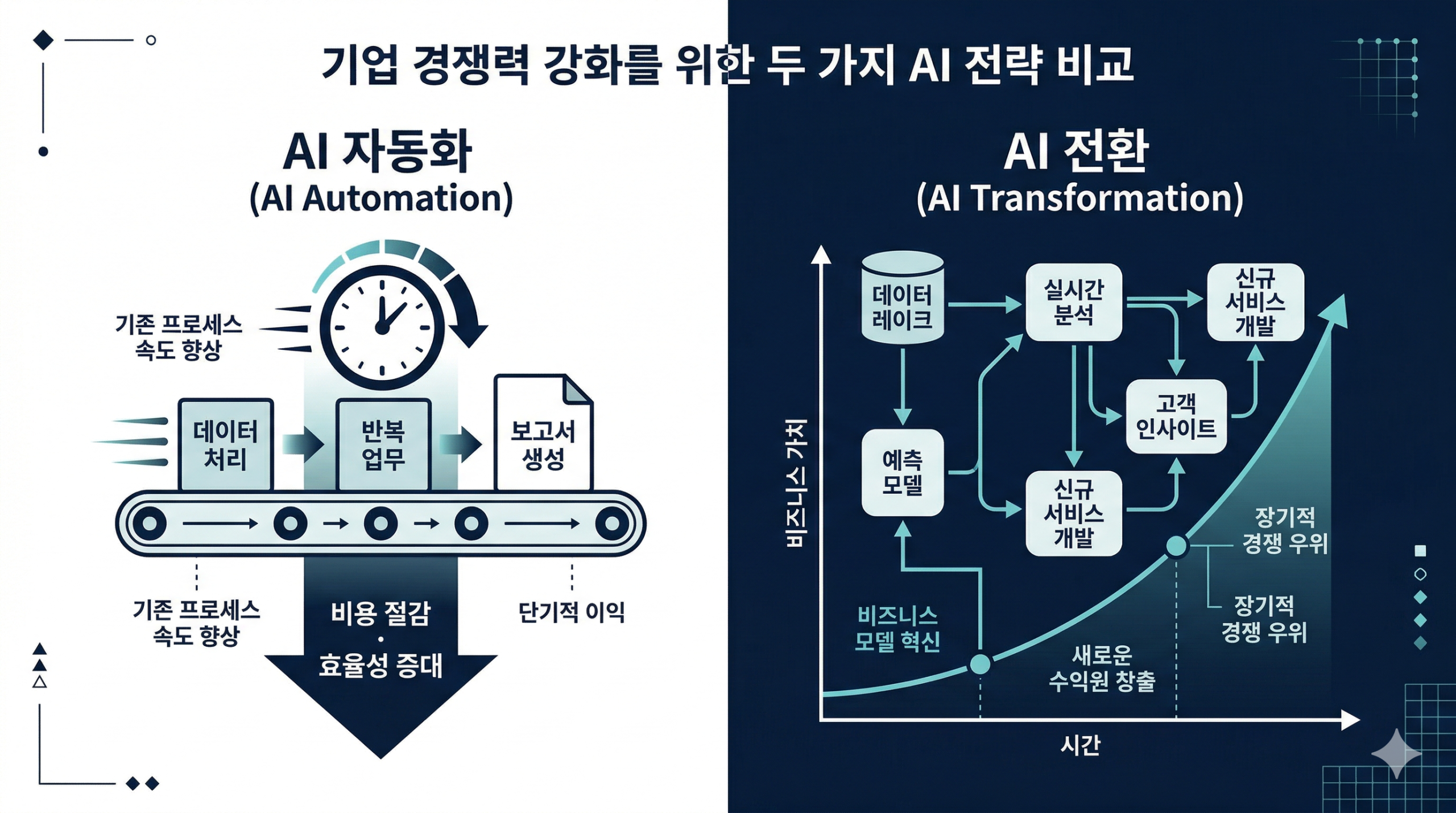
나이키의 전 마케팅 데이터 부사장은 AI 프로젝트 실패의 원인을 명확하게 지목했습니다. 자동화에만 집중했기 때문입니다.
AI 자동화는 기존에 하던 일을 더 빠르게, 더 저렴하게 만드는 것입니다. 마케팅 문구를 AI로 생성하거나, 고객 데이터를 AI로 분류하는 방식입니다. 단기적으로 효율은 올라갑니다. 그러나 경쟁사도 동일한 방식을 6개월 안에 따라 할 수 있습니다.
자동화는 결국 모든 기업이 갖춰야 할 기본 조건이 됩니다. 기본 조건은 경쟁 우위가 아닙니다.
과거 방식의 한계
과거에는 디지털 플랫폼을 구축하는 것 자체가 차별화였습니다. 앱을 만들고, 결제 시스템을 붙이고, 사용자 데이터를 쌓는 것만으로도 선발 우위가 생겼습니다.
지금은 다릅니다. 플랫폼은 누구나 만들 수 있습니다. 앱 출시는 진입장벽이 아닙니다. 기능의 유무보다 플랫폼이 어떤 구조로 설계됐는가가 중요해졌습니다.
그런데 대부분의 기업은 여전히 과거 방식의 질문을 던지고 있습니다. “어떤 기능을 추가할까?”
변화의 흐름
나이키는 스니커즈 앱을 구축하면서 한정판 구매 방식을 오프라인 줄 서기에서 디지털 추첨으로 전환했습니다. 문제는 그 다음이었습니다. 앱으로 전환하자 수요 예측 오차가 급격히 커졌고, 공정성에 대한 불만이 쌓였습니다.
나이키는 이 문제를 해결하기 위해 앱 안에서 사용자 취향 데이터를 직접 수집하는 구조를 만들었습니다. 게임, 설문, 참여 행동을 통해 개인화 데이터를 누적했고, 수요 예측 오차를 1년 만에 44% 줄였습니다. 공정성 점수와 참여도 점수를 기반으로 당첨 확률을 설계함으로써 만족도가 높아진 고객이 전체 매출에 기여하는 구조를 만들었습니다.
핵심은 AI 기능 자체가 아닙니다. 데이터를 수집할 수 있는 플랫폼 구조를 먼저 설계했다는 것입니다.
구조적 해석: 진짜 질문은 무엇인가
AI 자동화와 AI 전환은 근본적으로 다른 질문에서 출발합니다.
자동화는 “이 일을 어떻게 더 빠르게 할 수 있을까?”를 묻습니다. 전환은 “이 비즈니스를 아예 다른 방식으로 작동시킬 수 있을까?”를 묻습니다.
유통 플랫폼을 예로 들면, 단순히 견적서 작성을 자동화하는 것은 자동화입니다. 반면 누가 어떤 거래에 반복적으로 참여하는지, 어느 카테고리에서 성사율이 높은지, 어떤 조건이 갖춰졌을 때 거래가 완결되는지를 플랫폼이 학습하도록 설계하는 것은 전환입니다.
이 두 접근은 초기 기획 단계에서 갈립니다. 데이터 구조, 사용자 행동 설계, 관리자단 설계 방식이 처음부터 달라집니다.
실행 관점에서의 의미
AI 전환을 가능하게 하려면 플랫폼이 처음부터 학습 가능한 구조로 만들어져야 합니다.
구체적으로는 다음과 같은 설계 판단이 필요합니다. 사용자 행동 로그를 어떻게 수집하고 어디에 적재할 것인가. 어떤 사용자 인터랙션이 핵심 데이터가 되는가. 관리자단은 단순 운영 도구인가, 아니면 데이터 기반 의사결정 도구인가.
이런 질문은 기획 단계의 질문입니다. 개발이 완료된 이후에 AI를 추가하는 방식은 구조적 한계에 부딪힙니다.
나이키의 사례가 보여주는 것도 이것입니다. 나이키가 데이터 제휴를 통해 구매 패턴을 연결하고 개인화 마케팅을 가능하게 한 것은 플랫폼 기획 단계에서 데이터 흐름을 설계했기 때문입니다. AI는 그 구조 위에 얹힌 것입니다.
디비컨설팅의 관점
디비컨설팅은 100개 이상의 IT 프로젝트를 수행하면서 플랫폼 기획과 개발을 동시에 진행하는 구조를 유지하고 있습니다. 한국 PM팀이 기획을 주도하고, 인도 개발팀이 R&D를 병행합니다. 이 구조는 단순히 속도를 높이기 위한 것이 아닙니다.
기획과 개발이 분리되면 데이터 수집 구조, 사용자 행동 추적, 확장성을 고려한 아키텍처 설계가 후순위로 밀립니다. 기획자는 기능 목록을 만들고, 개발자는 그것을 구현하는 방식으로는 AI 전환을 위한 플랫폼을 만들 수 없습니다.
Stylemate(인플루언서 협찬 플랫폼)에서 소셜미디어 API를 연동해 협찬 완료 데이터를 플랫폼에 자동 연결하는 구조를 설계한 것, 패밀리(식품 성분 분석 플랫폼)에서 사용자의 식습관과 관심 식단 데이터를 수집하는 개인화 시스템을 기획 단계에서 설계한 것이 그 실제 사례입니다. 이런 플랫폼은 추후 AI 기능을 붙일 때 구조적 기반이 이미 갖춰져 있습니다.
결론: 플랫폼을 짓기 전에 먼저 이 질문을 해야 합니다
“이 플랫폼이 시간이 지날수록 더 똑똑해질 수 있는 구조인가?”
AI 기능 추가는 나중의 문제입니다. 데이터를 쌓을 수 있는 구조, 사용자 행동이 의미 있는 신호가 되는 설계, 학습이 가능한 관리자단이 먼저입니다.
자동화로는 현재의 비용을 줄일 수 있습니다. 전환은 미래의 경쟁 구조를 바꿉니다. 그 차이는 기획 단계에서 이미 결정됩니다.
