협찬은 나갔다. 그런데 왜 결과가 안 보이는가
인플루언서 마케팅 업계에는 공통된 역설이 있습니다.
협찬 제품은 발송됩니다. 계약서도 있습니다. 콘텐츠도 올라옵니다. 그런데 어떤 협찬이 실제 매출로 이어졌는지, 어떤 인플루언서가 브랜드에 진짜 가치를 만들었는지 파악하기 어렵습니다. 데이터는 분산되어 있고, 추적 구조가 없습니다.
이것은 인플루언서의 문제가 아닙니다. 운영 구조의 문제입니다.
이건 하나의 흐름이다
인플루언서 협찬 시장은 세 단계를 거쳐 진화해왔습니다.
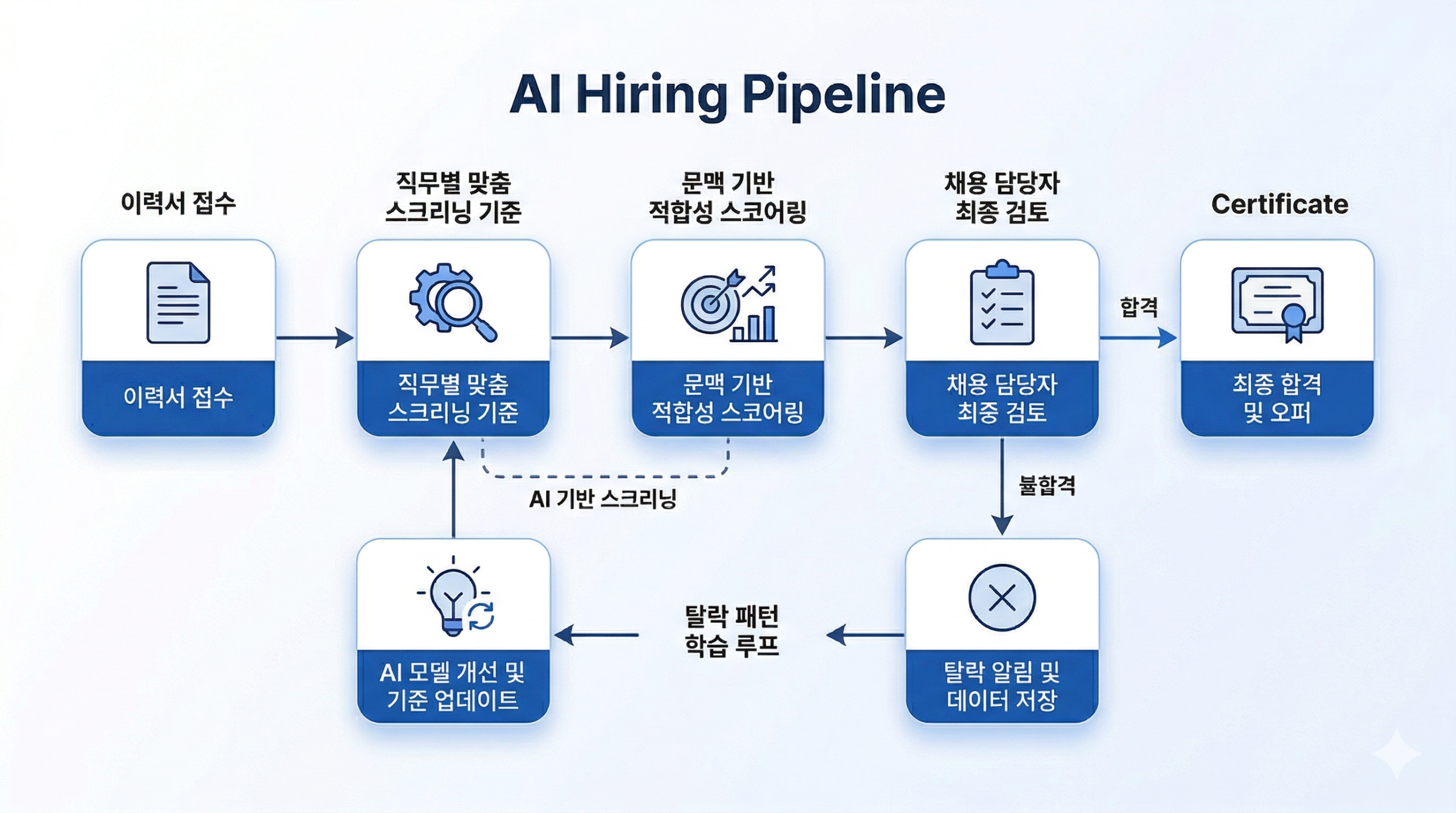
1단계는 인지도 중심입니다. 팔로워 수가 기준이었습니다. 많이 보이면 좋다는 논리였습니다. 2단계는 인게이지먼트 중심입니다. 좋아요, 댓글, 공유가 기준이 됐습니다. 3단계는 지금 시작되고 있는 전환 추적 중심입니다. 실제로 클릭이 발생했는지, 구매로 이어졌는지를 협찬 단위로 추적하는 구조입니다.
이 3단계의 핵심 도구가 AI Agent입니다.
기존 방식은 왜 무너지는가
지금까지의 협찬 운영 방식은 두 가지였습니다.
하나는 담당자 수동 관리입니다. 협찬 목록을 엑셀로 정리하고, 콘텐츠 업로드를 개별 확인하고, 성과를 수작업으로 취합합니다. 인플루언서 수가 늘어날수록 관리 공수가 선형으로 증가합니다. 10명은 가능하고, 100명은 불가능합니다.
다른 하나는 플랫폼 대시보드입니다. 전체 수치를 한 화면에 모아두지만, 개별 협찬의 맥락을 읽지 못합니다. 수치가 낮은 이유가 콘텐츠 때문인지, 타이밍 때문인지, 제품 자체 때문인지 판단하지 못합니다.
둘 다 ‘무슨 일이 일어났는가’는 알려주지만, ‘왜 일어났는가’와 ‘다음에 무엇을 바꿔야 하는가’는 답하지 못합니다.
작동 방식이 바뀌고 있다
AI Agent는 협찬 운영의 논리를 바꿉니다.
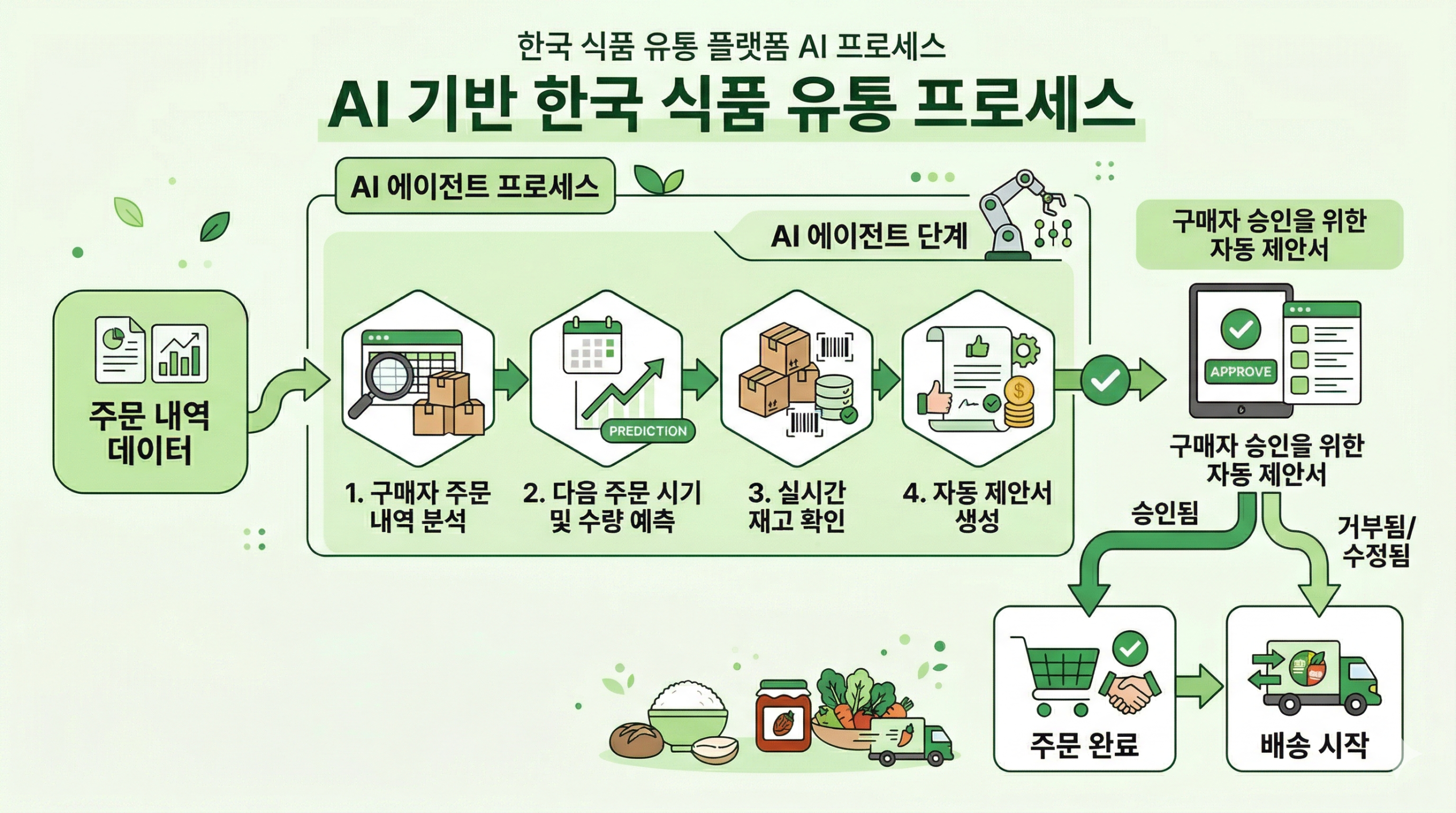
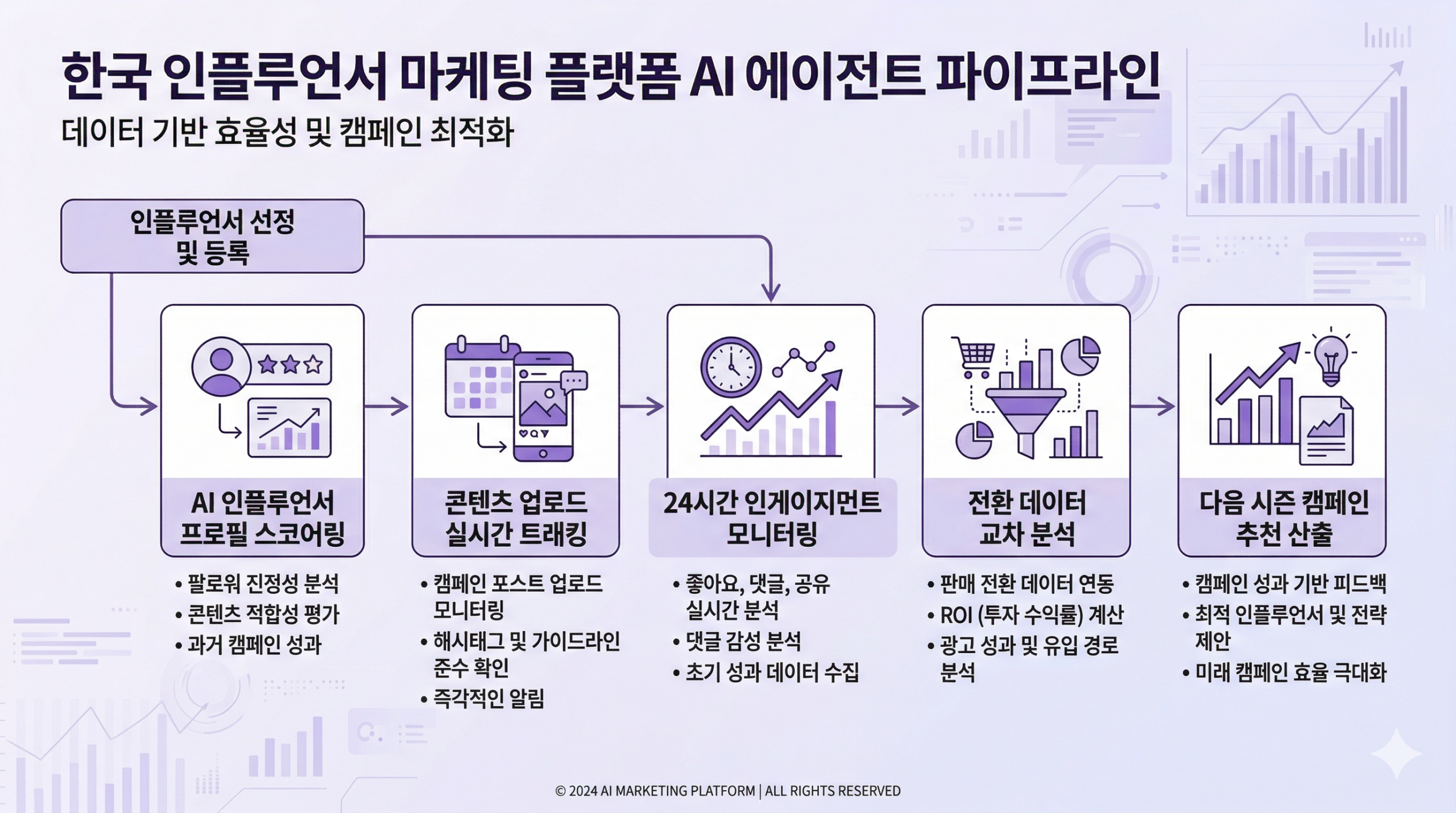
기존 운영은 협찬 후 성과를 수집하는 방식입니다. Agent는 협찬 전 적합도를 판단하고, 협찬 중 반응 패턴을 읽고, 협찬 후 학습을 구조화합니다.
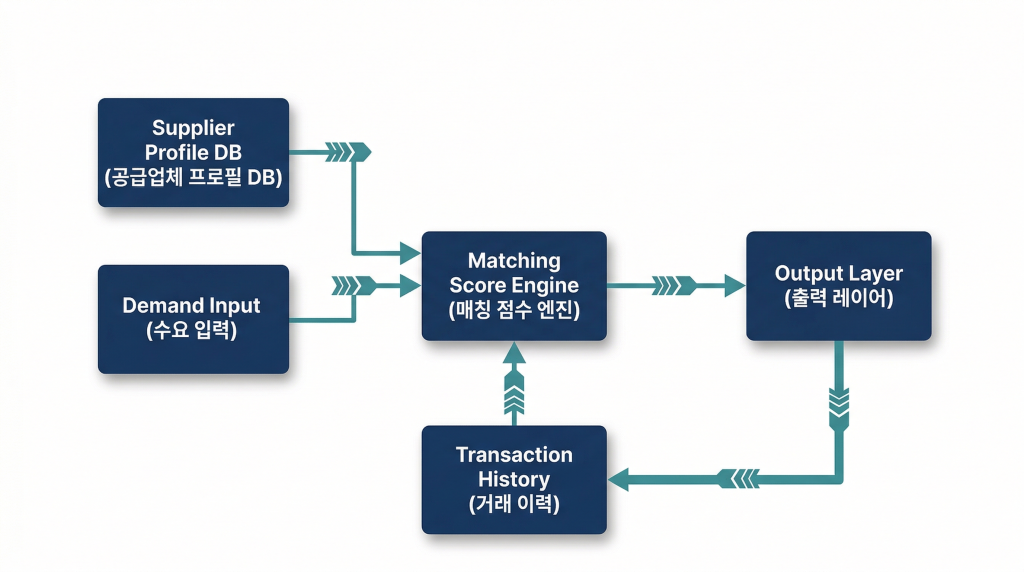
예를 들어 이런 흐름이 작동합니다. 인플루언서 프로필, 카테고리 적합도, 최근 6개월 콘텐츠 패턴, 팔로워 반응 유형을 종합해 협찬 우선순위를 제안합니다. 콘텐츠가 업로드되면 24시간 단위로 초기 반응 속도를 추적합니다. 일정 기간이 지나면 전환 데이터와 교차 분석해 해당 인플루언서의 실제 가치를 수치화합니다. 다음 협찬 시즌에 이 데이터가 의사결정 기준이 됩니다.
같은 예산으로 더 나은 결과를 만드는 구조입니다.
그래서 무엇을 바꿔야 하는가

협찬 운영 Agent를 도입하려면 두 가지 전제가 필요합니다.
첫째, 협찬 데이터의 구조화입니다. 인플루언서 프로필, 협찬 조건, 콘텐츠 링크, 전환 추적 코드가 하나의 체계로 연결되어야 합니다. 분산된 엑셀 파일과 카카오톡 대화로는 Agent가 작동하지 않습니다.
둘째, 전환 추적 체계의 설계입니다. UTM 파라미터, 전용 랜딩페이지, 인플루언서별 프로모션 코드 중 어떤 방식을 쓸지 결정해야 합니다. 추적 구조 없이는 Agent가 판단할 데이터가 존재하지 않습니다.
기술보다 설계가 먼저입니다.
격차는 여기서 벌어진다
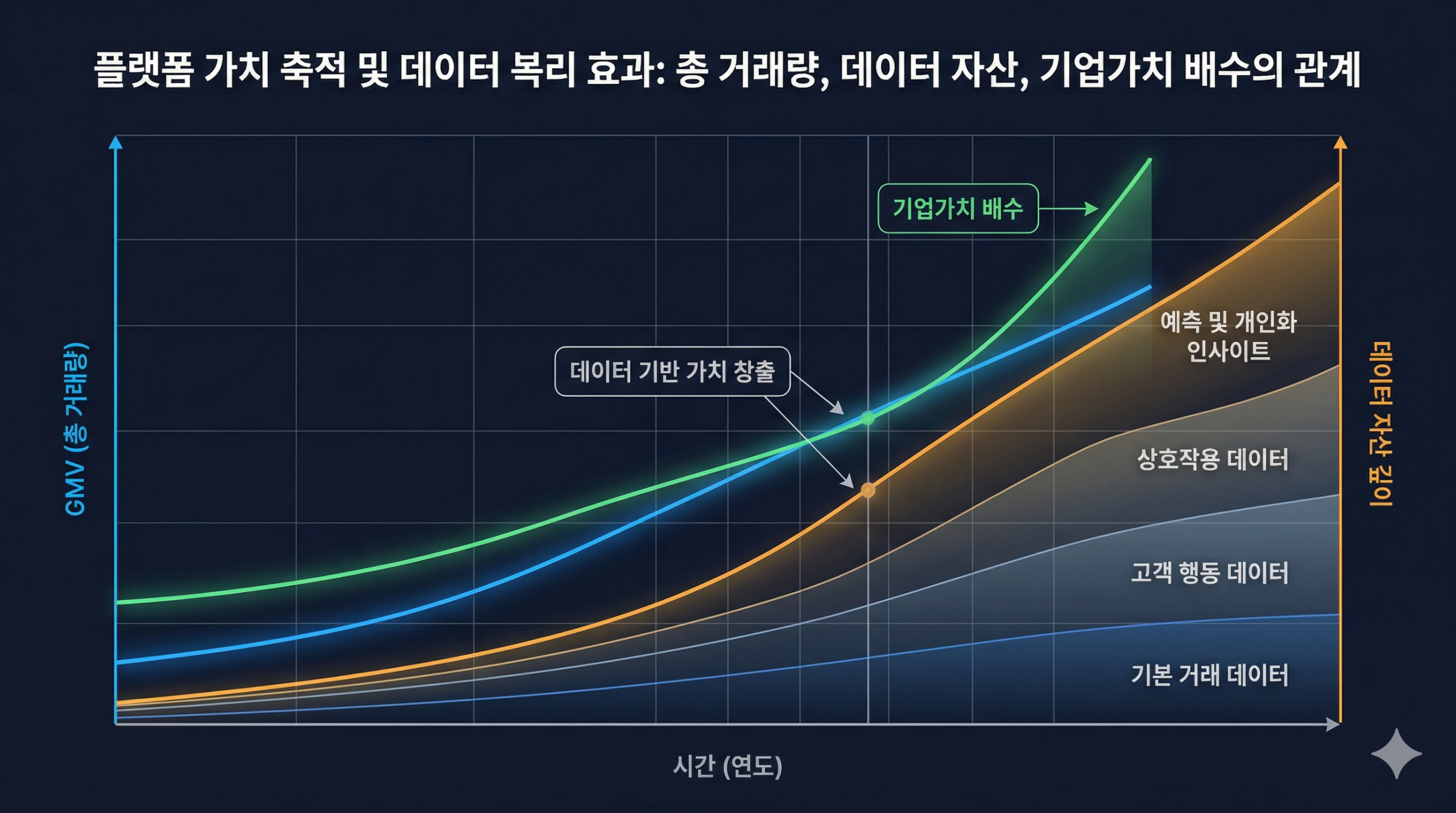
같은 예산을 쓰는 브랜드라도, 협찬 데이터를 구조화한 브랜드와 그렇지 않은 브랜드의 다음 시즌 의사결정 품질은 결국 달라집니다.
협찬 결과는 단순한 수치가 아닙니다. 다음 협찬의 기준이 됩니다. 그 기준을 만드는 것이 Agent 설계의 출발점입니다.
데이터를 쌓는 브랜드와, 데이터로 판단하는 브랜드의 차이. 그 차이는 지금 이 순간에도 벌어지고 있습니다.
이 문제는 정보의 문제가 아니라, 해석과 적용의 문제에 가깝습니다.
같은 상황을 어떻게 보고, 어떤 구조로 풀어내느냐에 따라 결과가 달라집니다.
관련된 고민이 있으시다면, 👉 여기에서 한 번 정리해보셔도 좋습니다.